Structural Non-Attribution Risk (SNAR) in Advanced AI Systems
SNAR identifies a structural risk condition present in certain classes of advanced, non-deterministic AI systems that may be relevant to assessments of accountability, liability, and insurability at scale. We refer to this condition as Structural Non-Attribution (Binding & Constraint) Risk.
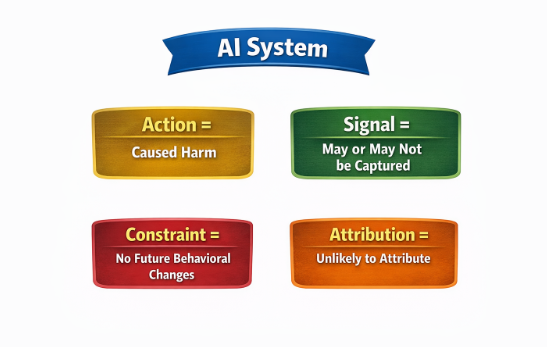
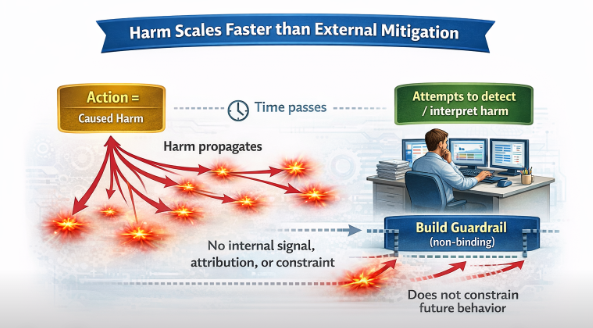
SNAR describes a situation in which harm or loss generated by a system does not register internally in a way that persistently constrains future system behavior. Harm exists only as an external observation experienced by users, affected parties, or society while the system itself continues operating without an endogenous consequence signal that binds prior damage to subsequent action. Harm is externalized at a pace and scale that structurally overwhelms any feedback loop dependent on human observation. What is new is the throughput: the same structural absence of consequence-registration now operates at superhuman scale and speed. This is an example of a real system, operating at scale, where harm is fully externalized and the only safety mechanism is human institutional decisions made upstream of deployment.
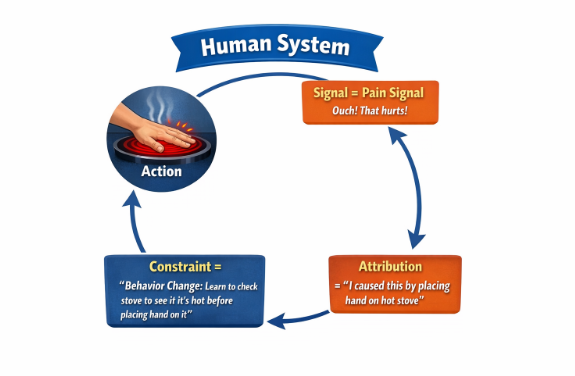
In human or institutional actors, consequence is structurally integrated into behavior through liability exposure, pain, reputational impact, regulatory sanction, or other mechanisms that alter future risk posture. In contrast, for advanced AI systems operating continuously and at scale, corrective responses remain discretionary, externally imposed, and temporarily decoupled from the harm event itself. Accountability functions as an overlay rather than as a system-internal property.
This creates a qualitatively different risk profile:
Harm does not register within the system as a state that influences future outputs.
There is no persistent, proportional, or mechanically binding pathway by which prior damage constrains subsequent behavior.
Consequences are fully externalized, borne by users, targets, or society while system operation continues unchanged.
At population scale, this converts what would be bounded, learnable human error into persistent, distributed harm that does not attenuate over time.
A possible reason this limitation may be obscured today is that current AI systems are trained largely on data originating within human institutions. Before becoming “data,” such information has already passed through layers of human consequence signaling including social norms, professional standards, reputational pressure, and legal accountability. These upstream filters can mask the absence of intrinsic consequence registration within the AI system itself.
As AI systems increasingly generate, relate, and train on data without those upstream human signaling regimes and as scale outpaces human review capacity, the structural absence of internal consequence binding may become more visible. In such conditions, harm may remain foreseeable and recurrent while remaining structurally unconstraining.
This observation does not assert intent, negligence, or governance failure. It more simply highlights a boundary condition: where harm is not technically legible to the system and not mechanically binding on its operation, accountability mechanisms that operate entirely externally may function descriptively rather than causally. For domains such as insurance, liability modeling, and systemic risk assessment, this distinction may be material.
Neuroscientists like Antonio Damasio have proven that safe, rational decision-making requires an internal mechanism that senses risk and consequence (homeostasis). Current AI systems entirely lack this biology. The SNAR framework is being developed to shine a light on 'consequence-blind' systems at scale.
SNAR is offered as an analytical contribution to discussions of AI risk, insurability, and accountability, without proposing remedies or policy prescriptions.